שלום חברים.
בפוסט זה אמשיך לדון על מבחני חדירה. בפוסט הקודם הצגתי במבוא את תהליך מבחן החדירה ותיארתי את השלב הראשון בתהליך – תכנון וזיהוי המטרות. בפוסט זה אדון על השלב השני – סריקת המטרות. החל מפוסט זה, אנחנו יוצאים מתאוריה ונכנסים יותר לשדה הטכני של תהליך מבחן החדירה. שנתחיל?
המטרה המרכזית בשלב הסריקה היא ללמוד על סביבת המטרה ולמצוא "חורים" ע"י אינטראקציה לוגית ישירה עם המטרה.
- חשיפת כתובות רשת של מערכות מרושתות, חומות אש, נתבים וכו' ...
- זיהוי טופולוגית רשת המטרה.
- יצירת מפה לוגית של הרשת תנחה אותנו איך לפעול בשלבים הבאים ותעניק אפקטיביות בכל הקשור לסדר וארגון הממצאים.
- זיהוי סוג מערכת ההפעלה במערכת שנחשפה.
- ממצאים אלה ינחו אותנו בהמשך (לרבות ניצול הפגיעות – Exploitation) .
- חשיפת פורטים\שירותי רשת פתוחים.
- נרצה ליצור רשימה של פורטים פתוחים (או "מקשיבים"), שכן כל פורט פתוח מהווה דלת כניסה פוטנציאלי למערכת.
- באופן ברור, התקשורת מתבצעת בפרוטוקול TCP ו\או UDP.
- בנוסף לחשיפת פורטים פתוחים, נרצה לדעת איזה שירות רשת נשען על הפורט ומהי גרסתו ברמת ה-Application (כגון HTTP version, SSH version, SMTP version וכו).
- זיהוי פוטנציאל פגיעות במערכות המטרה.
Network Sweeping – סריקה זו מזהה כתובות רשת בשימוש ע"י שליחת פאקטות לכל כתובות הרשת. אם קיבלנו תשובה חזרה – סביר להניח כי קיימת מערכת העושה שימוש באותה כתובת הרשת.
Network Tracing – סריקה זו נגזרת מסריקת Network Sweeping. בעזרתה ניתן למפות את הרשת ולזהות טופולוגיה.
Port Scanning – סריקה זו כשמה היא – חושפת פורטים פתוחים; פורט פתוח הינו שירות רשת ש"מקשיב" לבקשות רשת שונות. אם שירות רשת כזה או אחר פגיע – כאן בד"כ מתחיל השביל ללב המטרה :) .
OS Fingerprinting – לכל מערכת הפעלה - "ההתנהגות" שלה בסביבת הרשת. הווה אומר כי ע"י יצירת פאקטה ספציפית יכולה ללמד אותנו על המערכת עמה אנו מתקשרים וזאת ע"י אופן ה-Response שאנו מקבלים. זיהוי (גרסת) מערכת הפעלה מרחוק באמצעות טכניקה זאת – מכונה "Active OS Fingerprinting". חרף זאת, ישנה אפשרות לזהות את סוג מערכת ההפעלה באמצעות רחרוח (Sniffing) – ללא שליחת פאקטות כלשהן; טכניקה זו הינה פאסיבית.
Version Scanning – באופן ברור, הבודק אמור לדעת אילו שירותי רשת פועלים ובאילו יציאות (Ports). נכון, רוב השירותים פועלים בפורטים ידועים (Well-known ports) אך מנהלי רשת רבים משנים את יציאות ברירת המחדל. בעת יצירת אינטראקציה עם יציאות אלו באמצעות ה-Version scan, נוכל ללמוד על מאפייני הפורט ולדעת באיזו "שפה" הוא מדבר – קרי מהו הפרוטוקול.
Vulnerability Scanning – בסוג סריקה זה, אנו בודקים בד"כ אלפי פגיעויות (Vulnerabilities) פוטנציאליות כנגד המטרה. פגיעויות יכולות להיווצר כתוצאה מהגדרה לקויה או מתוכנה\שירות לא מעודכנים.
 |
| מוסכמות בדבר סדר תהליך הסריקה |
הרשו לי לתאר בקצרה את זרימת תהליך הסריקה: תחילה, אנחנו מבצעים Network sweeping ע"מ לזהות (כתובת רשת פרטית\ציבורית) מטרות פוטנציאליות. לאחר מכן ננסה לזהות את ארכיטקטורת הרשת, כלומר איך המטרות מקושרות זו עם זו. אח"כ, נבצע Port scanning ע"מ לגלות פורטים פתוחים ("דלתות" למטרה). לאחר מכן, נבצע OS fingerprinting ע"מ לזהות את סוג מערכות המטרה. אח"כ ננסה לגלות את גרסאות השירותים והפרוטוקולים אשר משמשים אותם. לבסוף – לאחר שליקטנו את הנתונים החיוניים – נוכל לבצע Vulnerability scan ע"מ לנסות לחשוף פגיעויות.
חשוב לי לציין שהסדר הנ"ל אינו פורמאלי, אף כי הוא מאוד נפוץ. ישנם בודקים שידלגו על צעד כזה או אחר בהתאם להיקף הבדיקה.
גישות מקובלות
בעת ביצוע המבדק, השתדלו לסרוק מערכות באמצעות כתובת הרשת שלהן – ולא באמצעות שמן.
- לדוגמה, יש לסרוק מטרה כלשהי ע"פ כתובתה ולא שם המערכת. כלומר, 192.168.10.10 ולא mycompany.local .
- אם בכל זאת תשתמשו בשם המערכת לצורך סריקה, סביר כי התוצאות תיפגענה. טכניקות DNS כגון Round-robin עשויות להפריע לתהליך הסריקה.
- לעומת זאת, אם עסקינן באפליקציות ווב (או אתרי אינטרנט) – סביר כי תצטרכו להשתמש בכתובת הדומיין וזאת מטעמי מאפייני פרוטוקול ה-HTTP העושה שימוש ב-Host header.
סריקות "כבדות"
- לעתים לא רחוקות, בודקים יצטרכו להתמודד עם סריקות "גדולות", "כבדות". בואו נעשה קצת חשבון ע"מ לאמוד את הסוגיה:
- בהינתן הוראה לסריקת 1,000 מערכות לרבות כל יציאותיהן (פורטים)
- 65,536 פורטים מסוג TCP ו-65,536 פורטים מסוג UDP (כולל 0)
- בהינתן הנחה גסה כי כל פורט יגזול שנייה אחת, זמן הסריקה יהיה:
- 65,536×2×1,000=131,072,000 [שניות]≈4.15 [שנים]
- אפילו אם נסרוק 100 פורטים בו-זמנית – עדיין ייקח לנו שבועיים (15 יום, ליתר דיוק) להשלים את הסריקה.
- ומה אם ר"ל נדרש לסרוק 10,000 מערכות? 100,000 מערכות?
גישה א' – הגבלת היקף הסריקה
הגישה הטריוויאלית ביותר היא לצמצם את מספר המטרות, הפורטים והשירותים לכדי סריקה יעילה אחת.
- יש לבחור "דוגמיות" מהמטרות;
- בחירת מערכות "מייצגות", הווה אומר – מערכות מרכזיות שמפעילות שירותים בסיסיים.
- נשים דגש על פורטים "מעניינים" כגון 21, 22, 23, 25, 80, 135, 443 וכו'...
- החיסרון: איך נקבע אילו מערכות הינן מייצגות? מה עם פורטים אחרים?
גישה ב' – סקירת חומות אש
גישה נוספת הנותנת פתרון לחסרונות גישה א' היא סקירת חוקי חומת האש (firewall rule set) ברשת ולהגדיר את הסריקה בהתאם לחוקי החומה.
- נבחר פורטים שסביר כי יעברו את סנן החומה.
- גישה זו ניחנת באפקטיביות רבה לגבי סריקות כבדות.
- חסרון: בד"כ הגישה הנ"ל לא מתאימה לבדיקות מסוג "Black box".
גישה ג' – האצת קצב הסריקה
במקום להגביל את היקף הסריקה, אפשרות נוספת היא לנסות ולהאיץ את קצב הסריקה.
- יש לבצע "טריק" קטן בחוקי חומת האש:
- נגדיר כי חומת האש תשיב קריאות RESET ו – ICMP port unreachable לפורטים סגורים.
- באופן אישי, אני לא ממליץ לפעול ע"פ הגישה הזאת.
גישה ד' – האצת קצב הסריקה (2)
גישה זו עושה שימוש בשיטות סריקה מהירות (Hyper-fast):
- קצב שליחת פאקטות מואצת והנמכת זמן ה-Timeout.
- סט כלים מצוין לגישה זו הוא ScanRand של דן קמינסקי.
- תוכנה אחת שולחת Syn-ים והאחרת מרחרחת (sniffing) לתגובת syn-ack.
- חסרון עיקרי: אפשרות גבוהה כי תגרמו ל-DoS (Denial of service)
- לכן, כדאי להיזהר מאוד בסביבות ה-production.
Network Tracing
ע"מ להבין את "הדרך" בה פאקטה עוברת ברשת, נרצה לבצע network tracing. כדי להבין איך ה-tracing פועל, נצטרך לנתח כמה שדות של ה- IP packet header.
להלן ה-header של פרוטוקול ה-IP בגרסה 4 (IPv4):
 |
| IP Header |
ובכן, 3 שדות מעניינים אותנו : "זמן חיים" (TTL), כתובת ה-IP של המען וכתובת ה-IP של הנמען – בעזרת שדות אלו נוכל לקבוע באופן דיי כללי את טופולוגית הרשת.
כתובת ה-IP של המען (Source IP Address) הינה שדה של 32 סיביות המייצג את כתובת מקור שליחת הפאקטה (בד"כ זו הכתובת של המחשב עמו אתם מבצעים סריקה). כתובת ה-IP של הנמען (Destination IP Address) גם היא מכילה 32 סיביות ומציגה את נמען הפאקטה.
שדה ה-TTL מכיל 8 סיביות ומציג לנו כמה "קפיצות – Hops" הפאקטה יכולה לעשות בדרכה לנמען לפני השמדתה. כאשר נתב מקבל פאקטה, בד"כ הוא מוריד ב-1 את ערך ה-TTL ושולח אותה לנתב הבא (בהתאם לצורך, כמובן). כאשר ערך ה-TTL מתאפס – הנתב "זורק" את הפאקטה מתעבורת הרשת ומחזיר למען הודעה: "TTL Exceeded in transit" (ICMP type 11).
Traceroute
טכניקת ה-traceroute עושה שימוש בהתנהגות הנתב כתלות בערך ה-TTL ע"מ לזהות נתבים נוספים בין המען למטרה. במערכות Linux ו-Unix, הטכניקה מיושמת ע"י פקודת traceroute ובמערכות Windows ע"י tracert.
אז איך הטכניקה עובדת בדיוק? ובכן, ע"מ לגלות את מספר הקפיצות של פאקטה כזו או אחרת מנתב אחד לשני – הפקודה שולחת פאקטה עם TTL של 1 ושולחת אותה לנמען. כאמור, נתב מוריד את הערך ב-1 כך שכעת הפאקטה "נזרקת" ונשלחת הודעה למען.
מצאנו כעת את הנתב הראשון. לאחר מכן הפקודה שולחת פאקטה עם TTL בערך 2 ... וכן הלאה.
יש נתבים שמוגדרים היטב ו-"יודעים" לא להחזיר תשובת ICMP TTL Exceed. במקרה כזה הפקודה תחזיר לנו פלט עם "*" המציינת כי אין מידע על כתובת הרשת.
מאפייני הטכניקה:
- גילוי ה"דרך" בה עוברת פאקטה בין שתי מערכות.
- מסייע לבודק "לבנות" את דיאגרמת ארכיטקטורת הרשת.
- מיושם ברוב מערכות ההפעלה.
 |
| כל נתב מפחית את ערך ה-TTL ב-1 |
פקודת ה-traceroute
הרשו לי להסביר בקצרה על יישום הטכניקה במערכות Linux/Unix בעזרת הפקודה traceroute:
- בברירת המחדל, הפקודה שולחת פאקטות UDP החל מפורט מספר 33434 והלאה (כאשר כל פעם מספר הפורט עולה ב-1).
- Flag-ים שימושיים:
- –f [N] : הגדרת ה-TTL ההתחלתי של הפאקטה הראשונה.
- –g [hostlist] : הגדרת מקור הניתוב (עם 8 hops לכל היותר)
- –I : שימוש ב-ICMP Echo request במקום UDP.
- –T: שימוש ב-TCP SYN במקום UDP (מאוד יעיל!)
- –m [N] : הגדרת מספר קפיצות מקסימלי
- –n : הדפסת כתובות לוגיות ספרתיות במקום שמות.
- –p [port] : הגדרת פורט הנמען.
- –w [N] : הגדרת זמן המתנה לתגובת ICMP (ברירת המחדל הינה 5 שניות).
Port Scanning
בסעיף זה אדון על סריקת פורטים פתוחים בעזרת טכניקות שונות המשמשות כלי עוצמתי בשם Nmap. נזכיר כי כל פורט פתוח מהווה מדיום פוטנציאלי להשגת היעד שלנו. ע"מ לעשות כך, נשלח פאקטות למחשב המטרה וננסה למצוא באמצעות התגובה אילו פורטים זמינים.
ע"מ שנבין את תהליך ה-port scanning, אין מנוס מלהסביר כמה סוגיות בנוגע לפרוטוקולים.
TCP, UDP ושכבות הפרוטוקול
סביר להניח כי אם הגעתם עד הלום, אתם מכירים ומבינים את מודל השכבות (OSI) , אך ברצוני לשים דגש על 3 שכבות:
 |
| TCP/IP model "VS." OSI model |
ניחשתם נכון – שכבת האפליקציה (7), התעבורה (4) והרשת (3).
אזכיר כי:
- רוב שירותי האינטרנט הם מסוג TCP ו-UDP ומועברים מקצה-לקצה באמצעות פרוטוקול IP.
- לכל פרוטוקול מאפיינים שונים – דבר שינחה את פעולת הסריקה שלנו.
- TCP – פרוטוקול אמין, ידוע כ-Connection oriented, שומר על עקביות הפאקטות ומשחזר פאקטים שלא הגיעו ליעדם.
- UDP – ידוע כ-Connectionless. לא אמין ואין הבטחה שפאקטים יגיעו ליעדם.
TCP Header
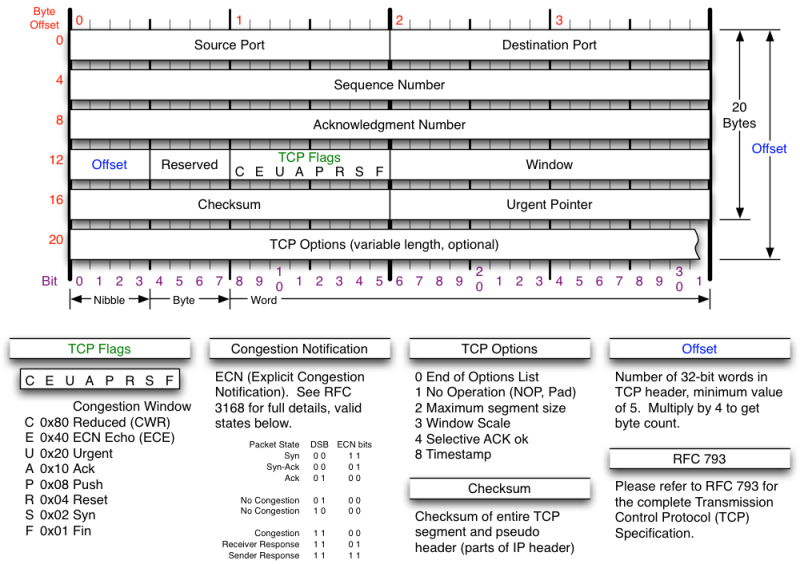 |
| TCP Header |
להלן מבנה ה-Header של פרוטוקול TCP; נשים לב כי הוא מכיל שדה מען ושדה נמען (16 סיביות כל אחד) המייצגים את פורט המקור ופורט היעד. בנוסף, קיים שדה עם מספר סידור (Sequence number), בעזרתו הפרוטוקול "עוקב" אחרי סדרה של פאקטות ע"מ לוודא כי כולן הגיעו – ובסדר הנכון.
אני רוצה להתעכב על שדה סופר-חשוב המכיל סיביות בקרה (Control bits) . זהו השדה TCP Flags.
TCP Control Bits
סיביות הבקרה, לעתים מכונות דגלוני בקרה או דגלוני תקשורת הינן סיביות המשמשות לזיהוי מצב ההתקשרות (TCP Connection state) שבעזרתן הפרוטוקול יודע לאיזה "חלק" הפאקטה שייכת ובכך ליצור תקשורת מהימנה בעת הקישור.
קיימים בסה"כ 8 דגלונים כאשר 2 מהם דיי "חדשים" (מוצגים ב-RFC 3168). סיביות הבקרה יכולות ללמד אותנו – הבודקים, על מצב הפורט. כל דיגלון ערכו 0 או 1 (בסופו של דבר, גודל כל דגלון הוא סיבית אחת). אציג בקצרה את 6 הדגלונים המוכרים:
SYN – מלשון Synchronize. כלומר – שליחת בקשה למערכת לסנכרון מספרי הסידור (Sequence number). דיגלון זה משמש בעת יצירת Session ותחילתה של התקשרות.
ACK – מלשון Acknowledgement. דיגלון חשוב. ערכו 1 אם הוא "יודע" על פאקטות שנשלחו קודם לכן (כחלק מסדרה של פאקטות).
RST – מלשון Reset. מודיע למערכת כי יש לאתחל את התקשורת (עקב שגיאה וכו...)
FIN – פיניטו :) . מודיע כי אין יותר נתונים שאמורים להישלח מהמקור.
PSH – סיבית זו מציינת כי אין רצף נתונים ולכן אין להחזיק בפאקטה ולחכות לפאקטות נוספות.
URG – מצביע Urgent מציין כי הנתונים שנשלחו הם בסדר עדיפות עליונה ויש לטפל בהם במהירות.
אני רוצה להתעכב על שדה סופר-חשוב המכיל סיביות בקרה (Control bits) . זהו השדה TCP Flags.
TCP Control Bits
סיביות הבקרה, לעתים מכונות דגלוני בקרה או דגלוני תקשורת הינן סיביות המשמשות לזיהוי מצב ההתקשרות (TCP Connection state) שבעזרתן הפרוטוקול יודע לאיזה "חלק" הפאקטה שייכת ובכך ליצור תקשורת מהימנה בעת הקישור.
 |
| סיביות הבקרה בפרוטוקול TCP |
קיימים בסה"כ 8 דגלונים כאשר 2 מהם דיי "חדשים" (מוצגים ב-RFC 3168). סיביות הבקרה יכולות ללמד אותנו – הבודקים, על מצב הפורט. כל דיגלון ערכו 0 או 1 (בסופו של דבר, גודל כל דגלון הוא סיבית אחת). אציג בקצרה את 6 הדגלונים המוכרים:
SYN – מלשון Synchronize. כלומר – שליחת בקשה למערכת לסנכרון מספרי הסידור (Sequence number). דיגלון זה משמש בעת יצירת Session ותחילתה של התקשרות.
ACK – מלשון Acknowledgement. דיגלון חשוב. ערכו 1 אם הוא "יודע" על פאקטות שנשלחו קודם לכן (כחלק מסדרה של פאקטות).
RST – מלשון Reset. מודיע למערכת כי יש לאתחל את התקשורת (עקב שגיאה וכו...)
FIN – פיניטו :) . מודיע כי אין יותר נתונים שאמורים להישלח מהמקור.
PSH – סיבית זו מציינת כי אין רצף נתונים ולכן אין להחזיק בפאקטה ולחכות לפאקטות נוספות.
URG – מצביע Urgent מציין כי הנתונים שנשלחו הם בסדר עדיפות עליונה ויש לטפל בהם במהירות.
תחילתה של תקשורת מופלאה – TCP Three-way handshake
כל חיבור TCP (כזה שהוא לגיטימי, כן?) מתחיל התקשרות באמצעות "לחיצת יד משולשת" שמטרתה העיקרית הינה לקבוע את מספרי הסידור בין שתי המערכות המתקשרות כך שפאקטות ש"נפלו" בדרך יוכלו להישלח שוב.
נגדיר מחשב A כך שהוא נדרש ליצור התקשרות (להתחבר, בלשון לא פורמאלית) עם מחשב B. הפאקטה הראשונה שמחשב A ישלח - יכיל סיבית בקרה מסוג SYN וכן מספר סידור התחלתי (לעתים נקרא Initial Sequence Number או ISN) בגודל 32 סיביות. אציין כי מספרי הסידור הם פסאדו-רנדומליים, כלומר קיימת תבנית מסודרת בעת התקשורת אך המספר הוא אקראי לגמרי. דגל ה-ACK יהיה 0 כיוון שזוהי פאקטה התחלתית שאינה חלק מפאקטות שכבר נשלחו.
איך יגיב מחשב B ? אם פורט היעד פתוח (כלומר המחשב "מאזין" לפורט זה), הוא חייב להחזיר פאקטת תשובה מסוג SYN-ACK (פאקטה שסיביות הבקרה SYN ו-ACK הן 1). פאקטה זו תכיל ISN שמחשב B יוצר. בנוסף ערך ה-ACK בפאקטה זו יכיל את ה-ISN של מחשב A ותעלה את ערכה באחד – ISN(A)+1 , ויציין כי למחשב B ידוע (ACK) על פאקטת SYN שנשלחה ממחשב A.
ע"מ להשלים את "לחיצת היד", מחשב A משיב עם פאקטת ACK שמספר הסידור שלה יהיה ISN(A)+1. ערך ה-ACK ייקבע ל- ISN(B)+1 המעיד כי זהו חלק מפאקטת SYN-ACK .
כעת, שני הצדדים "החליפו ביניהם" מספרי סידור כך שכל פאקטה שנשלחת ממחשב A ל-B תכיל מספר סידור החל מ- ISN(A)+1 , ובאופן דומה כל פאקטה שמחשב B מחזיר תכיל מספר סידור שערכו ההתחלתי יהיה ISN(B)+1.
אם הסעיף הנ"ל הוא בגדר tl;dr עבורכם, הנה תמונה שתמחיש דבריי:
 |
| לחיצת יד משולשת בין לקוח ל-שרת |
ע"פ RFC 793 המתאר את פרוטוקול ה-TCP וכל האמור לעיל, נוכל לקבוע את המשפט הבא:
פורט במערכת הינו פתוח (כלומר, קיים שירות כזה כך שהמערכת מאזינה לתשדורות) אם ורק אם המערכת מחזירה תשובה מסוג SYN-ACK לפאקטה מסוג SYN שנשלחה אליה.
המשפט הנ"ל מעניק טכניקה יעילה לזיהוי שירותי רשת (פורטים).
הרשו לי לתאר וויזואלית ארבעה תרחישים בעת סריקת פורטים וננסה להסיק מהו מצב הפורט בהתאם לפאקטת התשובה:
 קיבלנו תשובה מסוג SYN-ACK, ממש "by the book" . הפורט פתוח!
קיבלנו תשובה מסוג SYN-ACK, ממש "by the book" . הפורט פתוח!




UDP
UDP הוא פרוטוקול פשוט. הכי פשוט. לא אתעכב עליו הרבה.
חשוב לזכור כי הפרוטוקול הוא Connectionless, כלומר אין דבר כזה חיבור ע"י UDP מהסיבה שהפרוטוקול לא מאופיין באפשרויות מעקב אחרי פאקטות. בד"כ הוא איטי יותר כשמדובר בסריקה וכמובן – לא אמין. אין סיביות בקרה ואין שום אינדיקציה על "מצב" החיבור. פשוט.
 |
| UDP Header |
נבחין כי ב-UDP ארבעה שדות בעלי 16 סיביות כ"א. פורט המקור, פורט היעד, גודל ו-Checksum.
אז איך ניעזר בפרוטוקול למציאת פורטים פתוחים? פשוט, לפי התשובה שנקבל.



- הפורט סגור.
- חומת אש חוסמת שליחת פאקטות UDP
- חומת אש חוסמת קבלת פאקטות UDP
- הפורט פתוח, אך דורש ארגומנטים מסוימים בשדה ה-DATA ...
אגב, זו הסיבה המרכזית בגינה רוב המבדקים לא מתעכבים על סריקות הנשענות על פרוטוקול זה.
עד כאן, חברים. אני כולי תקווה כי בפוסט זה קיבלתם הסבר על המשמעות הרחבה של תהליך הסריקה. הרחבתי על גישות סריקה, Network tracing ו- Port scanning. הצגתי בעיקר עקרונות מרכזיים בתהליך הסריקה. יש עוד הרבה לדון על תהליך הסריקה. בפוסטים הבאים אמשיך לדון התהליך כחלק מהתהליך הכולל של מבדק החדירה וכחלק מסדרה של פוסטים על הנושא.
עד אז. שתהיה שנה אזרחית מאובטחת לכולם.